Mistral AI Hackathon - Finetune Mistral 3B model
#Mistral AI Hackathon - Finetune Mistral 3B model
Mistral AI is launching its largest hackathon ever. This time, I participated in the Mistral AI Hackathon, sponsored by Mistral, Weights & Biases (wandb), and others. Here, I share my hackathon experience and provide an overview of the project I built. This article was written by me, not AI.

Mistral is one of the major AI companies shaping the age of LLMs, providing cutting-edge research models. I knew they support numerous local models and offer many LLM APIs.
As someone who participates in Kaggle regularly, Weights & Biases has caught my attention several times. wandb, one of their products, has significantly improved ML developer productivity. It is worth noting that wandb is used by over 900,000 machine learning practitioners, researchers, and experts.

Improve ML developer productivity with Weights & Biases: A computer vision example on Amazon SageMaker | Amazon Web Services
July 2023: This post was reviewed for accuracy. This post is co-written with Thomas Capelle at Weights & Biases. As more organizations use deep learning techniques such as computer vision and natural language processing, the machine learning (ML) developer persona needs scalable tooling around experiment tracking, lineage, and collaboration. Experiment tracking includes metadata such as […]
Before diving into the project details, let me briefly mention the project tracks. This hackathon had two tracks:
Mistral AI Track
Build anything with the Mistral API. Create agents, tools, products, experiments—no constraints. Just ship something ambitious, creative, and impactful.
Fine-Tuning by Weights & Biases
This track was for technically strong builders who wanted to fine-tune Ministral, Mistral Small, Mistral Medium, Codestral, or other Mistral models on a specific task of their choice.
#Motivation behind this Hackathon
My motivation for this hackathon was not to build a vibe-coded app or create something superficial. I wanted a meaningful experience—something aligned with my interests and the friends I made at the hackathon.
Yes, I initially considered building a mobile app where users could interact with Mistral AI through voice, or a game where NPCs speak based on a knowledge base. However, those ideas felt less impactful than what I ultimately wanted to build.
Since this hackathon was sponsored by Mistral and Weights & Biases, I wanted to fine-tune a model that could contribute to society—something useful not only for developers but for broader audiences. Additionally, having a fine-tuned model meant receiving incredible support from the Mistral and Weights & Biases teams, which I truly appreciated.
The biggest challenge was creativity. At first, I didn’t know what to fine-tune or build because:
- I had no prior experience fine-tuning models.
- Although I call myself an AI engineer, my current job does not involve machine learning.
- While I frequently participate in Kaggle competitions, most of my experience is with tabular data.
This was my first time working deeply with a natural language model where I had full control.
#Problem statement
Here’s how I arrived at my problem statement.
I began by reading the Mistral AI model paper written by Albert Q. Jiang, Alexandre Sablayrolles, and others. My first impression was that the model was highly capable across many tasks. However, I became particularly interested in how distillation affects model performance and knowledge retention. I learned that distillation significantly impacts both capability and knowledge representation.
Mistral 7B
We introduce Mistral 7B v0.1, a 7-billion-parameter language model engineered for superior performance and efficiency. Mistral 7B outperforms Llama 2 13B across all evaluated benchmarks, and Llama 1 34B in reasoning, mathematics, and code generation. Our model leverages grouped-query attention (GQA) for faster inference, coupled with sliding window attention (SWA) to effectively handle sequences of arbitrary length with a reduced inference cost. We also provide a model fine-tuned to follow instructions, Mistral 7B -- Instruct, that surpasses the Llama 2 13B -- Chat model both on human and automated benchmarks. Our models are released under the Apache 2.0 license.
One of my personal policies for the hackathon was that my idea had to be deeply personal—something the judges could empathize with.
Currently, I review a large amount of AI-generated code written by my teammates. Although tools like CodeRabbit and other AI review systems help, I still need to manually review changes. The worst part is that AI-generated code can introduce serious security risks.

How AI-Generated Code Is Unleashing A Tsunami Of Security Risks
AI-generated code is opening up a host of vulnerabilities, and security continually lags behind software development. It’s time to get uncomfortable.
#How project went
I started building a self-improving vulnerability detection system. I fine-tuned the Mistral 3B model to detect code vulnerabilities with deeper semantic understanding, then built a fully automated improvement loop using Weights & Biases.
The first step was constructing a data pipeline and scraping data for training and validation.
CVEfixes is a comprehensive vulnerability dataset automatically collected and curated from Common Vulnerabilities and Exposures (CVE) records in the public U.S. National Vulnerability Database (NVD).

CVEfixes Dataset
CVEfixes: Collection of Vulnerabilities and Their Fixes from Open-Source
Building the dataset was challenging because it contained over 40GB of data. I converted the original database into an SQL database, which was extremely space-consuming. Additionally, using Semgrep—one of the security tools I relied on—was labor-intensive. I probably spent six hours just building the database.
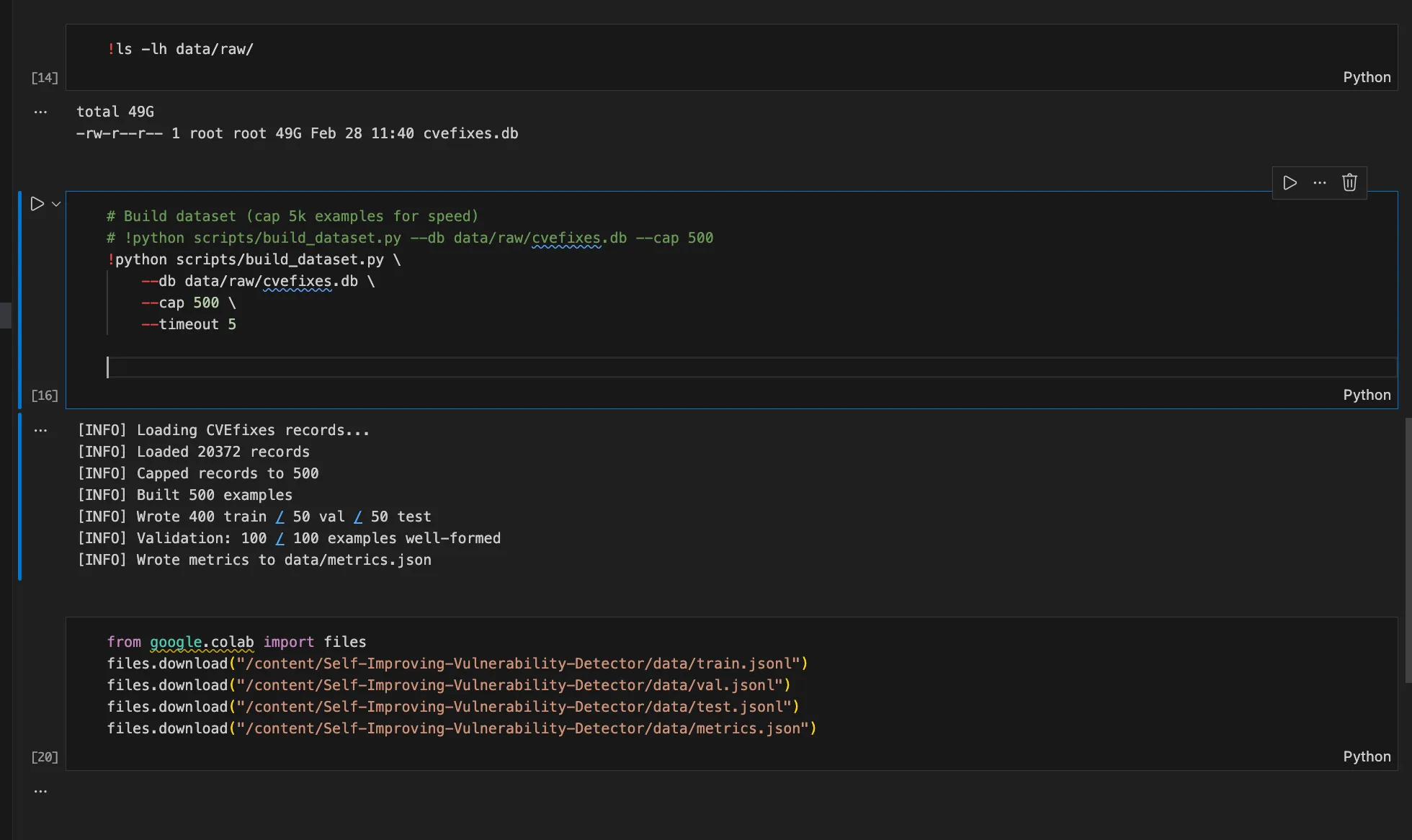
After preparing the database, I finally started fine-tuning the model and set up wandb.
One of the coolest features of wandb was the ability to monitor training loss, evaluation loss, and other metrics in real time. For example, I could start training, go wash the dishes, and still monitor the progress from my screen. Watching the evaluation loss decrease as training steps increased was incredibly satisfying.
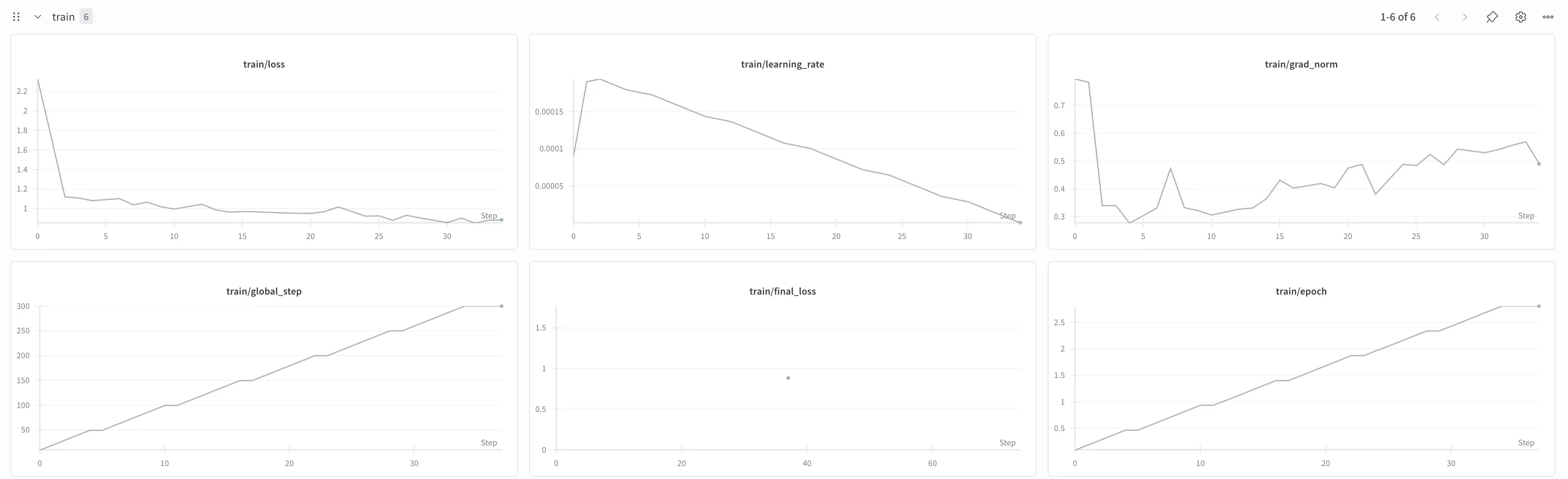
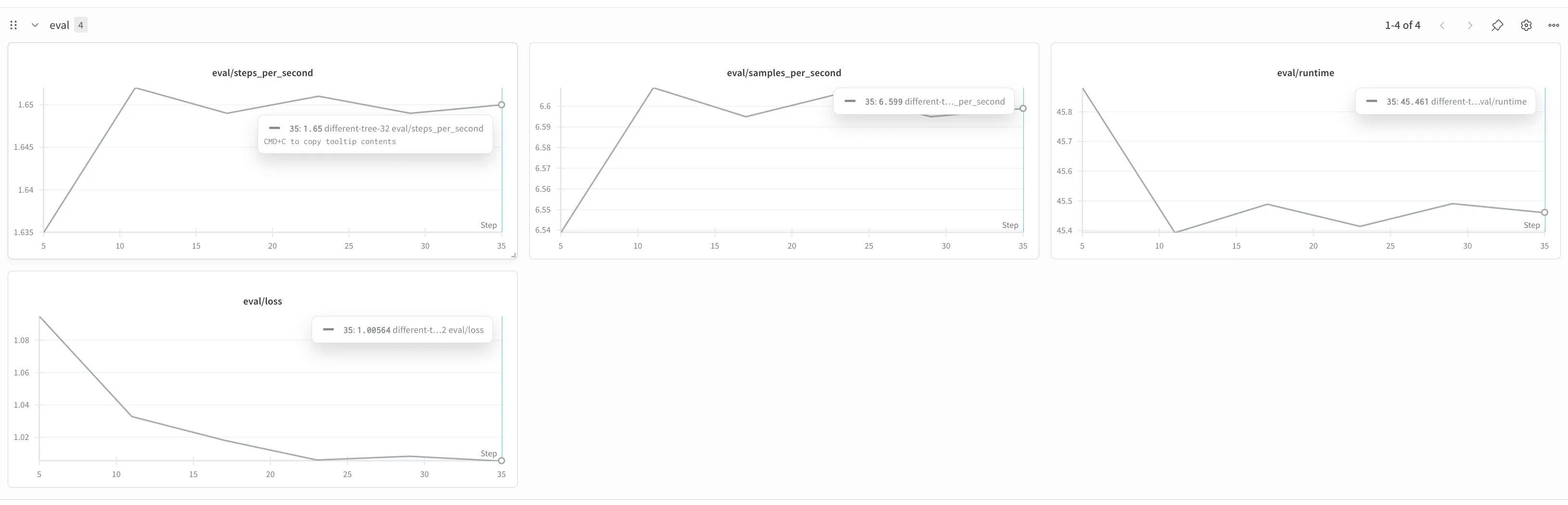
Another helpful aspect was that I could visually detect when the model’s behavior wasn’t improving—not just from raw logs but from the wandb graphs. This significantly helped during the fine-tuning process.
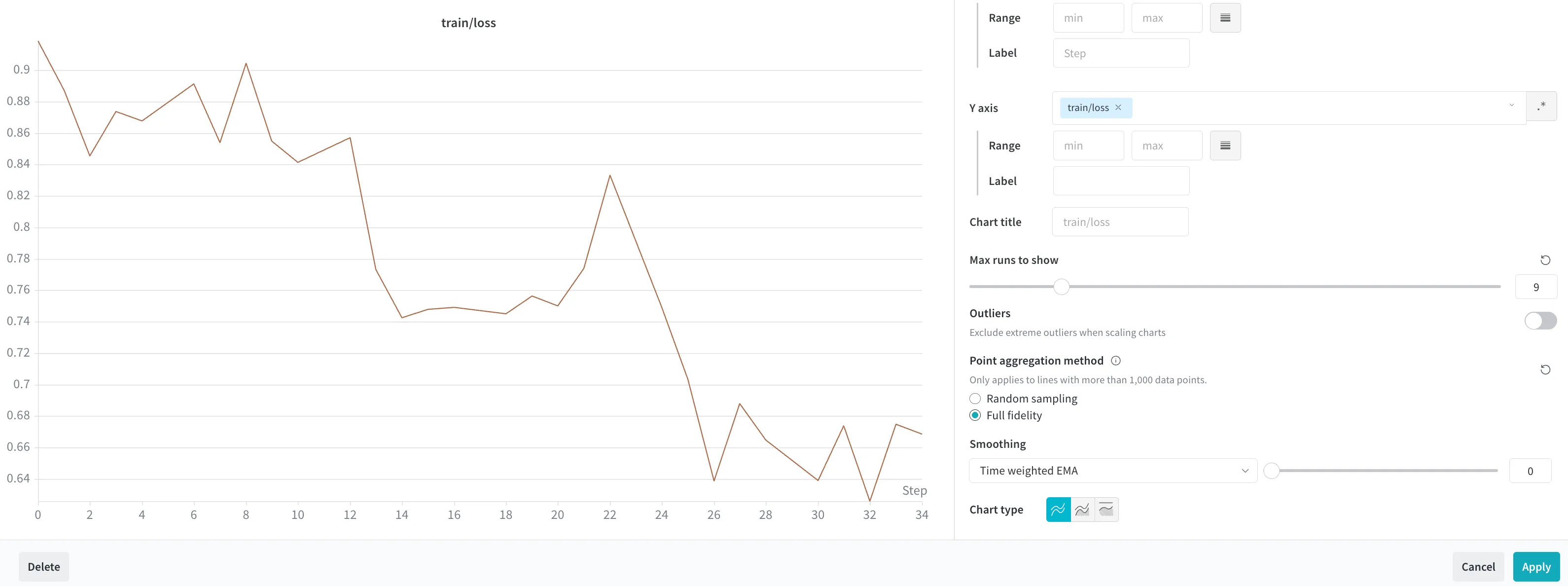
After running the GPU for 10 hours, I successfully trained a model with a training loss of 0.84 and a validation loss of 0.95, which I was satisfied with given the short hackathon timeframe.
I tested several cases. While the model didn’t perform as perfectly as I had hoped, it successfully passed two out of three test cases. I then submitted the model to Hugging Face!


jojotostar/vuln-detector-lora · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
#What's next
I want to bring this project to the next level—where developers can integrate a small language model into their GitHub Actions pipeline. The model could automatically review code changes and provide a safer development environment.
I also plan to build a pipeline where the model continuously learns from recent code changes and pushes updated versions to Hugging Face, effectively acting as version control for the model itself.
I would like to sincerely thank the teams at Mistral AI and Weights & Biases for organizing such an inspiring hackathon and for providing incredible technical support throughout the event. The opportunity to experiment, learn, and fine-tune a model with guidance from experts was truly invaluable.