X Developer Project | Recreating Twitter search engine and how we failed it
#Introduction
When our team initially brainstormed ideas for improving the Twitter platform, we considered several aspects, such as optimizing Twitter job recommendations and refining the overall recommendation system, cloning users on Twitter and create a virtual clone bot, unethical content remover. However, we encountered practical limitations. Specifically, the Twitter Jobs feature lacked robustness, making it difficult to extract meaningful job-related data. Additionally, our idea to filter and remove unethical content faced a direct conflict with Twitter's existing policies, leading us to abandon this approach.

Despite these challenges, an engineer from Twitter suggested focusing on improving the search functionality, a component of the platform that was underperforming. This advice shifted our project's direction towards enhancing how users find relevant content on Twitter. Based on our analysis using Cosine similarity, a method for measuring the relevance of posts to user-specified keywords—indicated a relevance score of 80%. This metric, while seemingly high, did not align with the actual user experience, which often resulted in retrieving non-relevant results during searches.
This discrepancy raised important questions about the effectiveness of the current search algorithms and highlighted the need for a more nuanced approach to assess and improve search relevance. We realized that while Cosine similarity provided a quantitative measure of relevance, the qualitative aspect of user satisfaction was not adequately addressed.
#Building Twitter Search Engine
In building the search engine for the project at Stanford University, where I previously worked on LLM and Law applications, the focus was heavily on backend development. We prioritized deep conceptualization of our ideas, often at the expense of front-end elaboration. From this experience, I recognized the need to balance my efforts better, leading to an improved approach in the current project where I devoted more attention to the front-end design.
Utilizing Figma, which had already been set up, allowed me to efficiently sketch out the front-end interface. Implementing the design using TypeScript and React, tools I am familiar with, streamlined the development process significantly. This familiarity with the tools enabled a quick and efficient setup, allowing me to shift focus to the more complex parts of the project sooner.
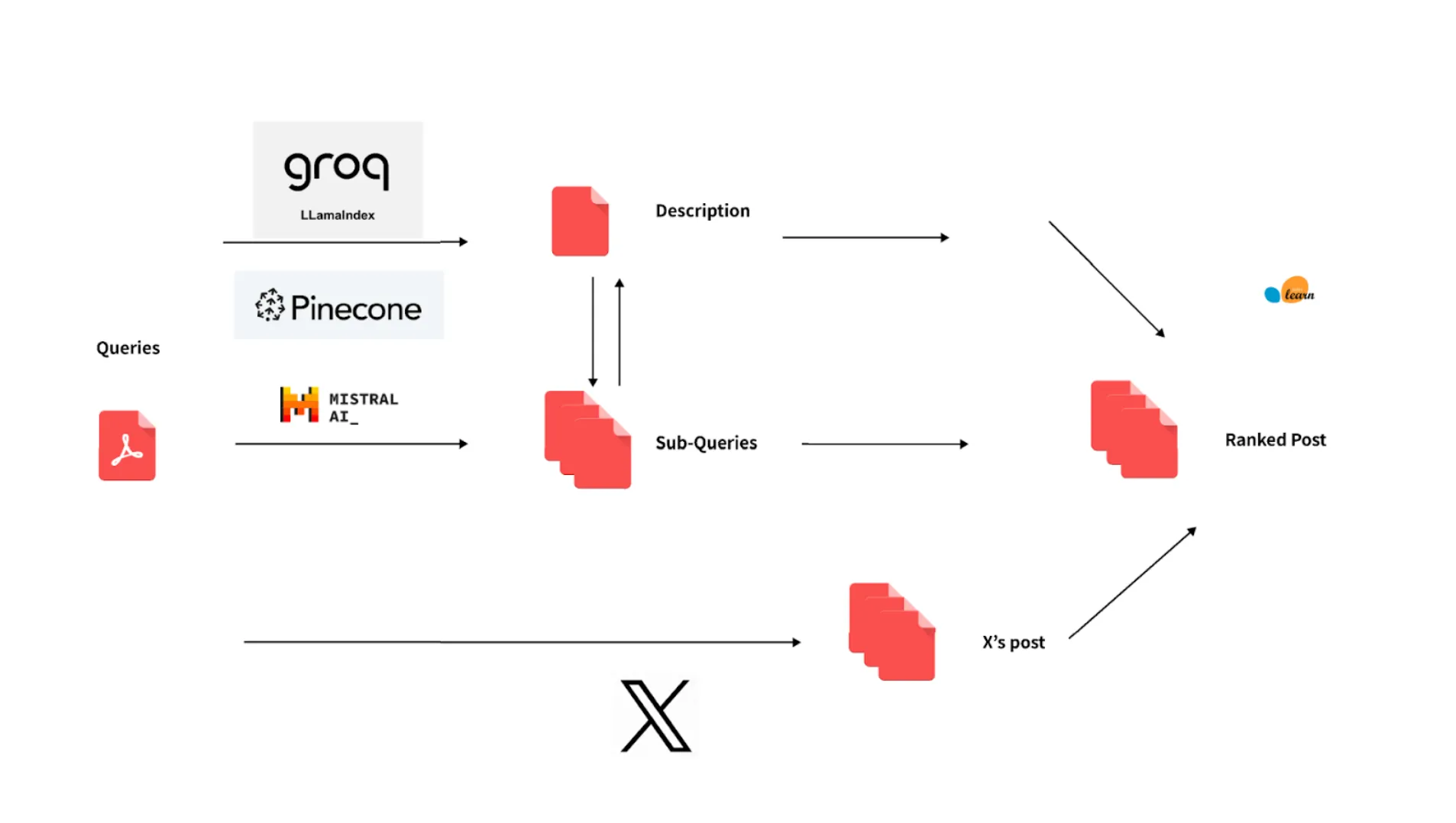
The core functionality of our search engine revolves around processing and retrieving Twitter posts relevant to user queries. As illustrated in our architecture diagram, the user input is first parsed into a main query. Using Perplexity AI and the Mixtra Model, this main query is then broken down into about 40 subqueries, each representing different facets or keywords relevant to the original search terms.
Each subquery triggers calls to Twitter's API to fetch tweets that match or are related to the subquery's keywords. The system aggregates these tweets, analyzing and correlating them with the subqueries to determine their relevance. Posts are then ranked based on a calculated relevance score, determining their placement in the search results. This method ensures that the most pertinent information is prioritized, enhancing the user's search experience and providing targeted, useful content related to their initial inquiry.
#Judging and how we did it
I remember one of the judges said to me after he saw it, "Yes, it's true, Twitter's search function is not very good. I remember one of the judges said, "Yes, the search function on Twitter is not very good," which made a good overall impression on me. Another judge commented that the overall usability was good, but questioned why the use of cosines when ranking searches was used, and also wondered if the evaluation method using only cosines was not sufficient.

#Other use of Twitter API and selected project
#Xecute: twitter language
Our team explored an innovative idea of developing a Twitter bot that would generate animations in response to specific code inputs tweeted by users. This concept was intriguing as it proposed integrating a form of computer language directly into Twitter, transforming the platform into an interactive coding environment.

Although the idea captivated the team, we were initially uncertain about the technical feasibility and complexity of implementing such a feature. The challenge lay in determining whether Twitter could support the advanced functionality required for real-time processing and rendering of animations based on user-generated code inputs.

#Unethical content remover
Our team initially considered enhancing Twitter's filtering capabilities to allow users to opt out of viewing sensitive content, despite potential conflicts with existing platform policies. Although this idea was ambitious, it highlighted the platform's need for more user-tailored content management. Remarkably, within just two days, significant progress was made, demonstrating the platform's adaptability. Additionally, the integration of Large Language Models (LLM) with Groq's technology proved effective in discerning and aligning with user preferences, showing promise for future enhancements in content filtering and personalization on social media platforms. This experience underscored the importance of adaptive, user-focused design in digital spaces.
#Felix
The useflixbot is an innovative Twitter bot developed by Andrew, inspired by popular features on TikTok and YouTube. This bot enhances Twitter's multimedia experience by creating short videos that feature a person's face reading and lip-syncing to the content of tweets. Andrew was motivated to develop useflixbot after observing that 90% of Twitter posts include multimedia elements like photos and videos. His goal was to explore whether Twitter could leverage similar technology to generate engaging video content, potentially increasing user interaction and enhancing the platform's visual content delivery.